Read More《构建LLM:每个AI项目都需要的知识图谱基础》
Positive Comments: Knowledge Graphs Inject “Trustworthy Genes” into LLMs, Reconstructing a New Paradigm for AI Applications in Professional Fields
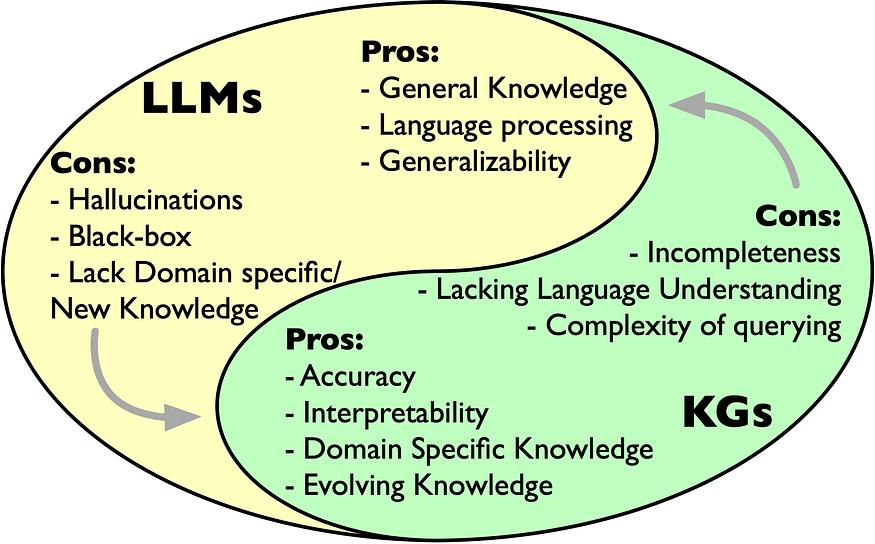
The incident where lawyer Schwartz was judicially disciplined for relying on forged legal cases generated by an LLM exposed the “trust crisis” of general large language models in professional fields. However, the profound value of this incident lies in pointing out an upgrade direction for the application of AI technology in key fields—when LLMs are deeply integrated with knowledge graphs (KGs), they can not only effectively solve the “hallucination” problem but also build an intelligent system that is “verifiable, interpretable, and traceable,” which is of milestone significance for the implementation of AI in professional fields such as law, medicine, and finance.
First of all, knowledge graphs provide “factual anchor points” for LLMs, fundamentally alleviating the persistent “hallucination” problem. The core defect of general LLMs lies in the “black – box nature” of their knowledge storage—information is implicitly stored in the form of parameter weights, and the source or logic cannot be directly verified. In contrast, knowledge graphs transform authoritative knowledge in professional fields (such as legal precedents, medical guidelines, and financial regulations) into auditable graph data through the structured expression of “entity – relationship – attribute.” For example, in the legal scenario, a knowledge graph can connect key information such as “case name, case number, court, judgment time, core dispute points, and related precedents” of each precedent through explicit relationships, forming a “precedent network.” When an LLM processes a query about “legal precedents for a certain aviation accident case,” the system can quickly retrieve and verify the authenticity of precedents through the knowledge graph, avoiding the generation of non – existent cases. As mentioned in the news about the concept of a hybrid system: “When asked ‘Is the case real?’, the system can clearly answer ‘unverified’.” This “factual verification” ability based on knowledge graphs cannot be achieved by a single LLM.
Secondly, the “dynamic evolution” characteristic of knowledge graphs solves the “lag” problem of knowledge update in LLMs. Knowledge in professional fields (such as new laws and revisions of medical guidelines) is highly time – sensitive, while the knowledge update of LLMs depends on retraining or fine – tuning, which is costly and time – consuming. Knowledge graphs, through the “incremental update” mechanism, can dynamically add new entities (such as new precedents) and update relationships (such as the association of “being overturned by subsequent precedents”) without changing the underlying structure, ensuring that the knowledge is always “fresh.” For example, when the Supreme People’s Court issues a new judicial interpretation, the knowledge graph can quickly associate it with the existing precedent network and mark attributes such as “scope of application” and “hierarchy of validity.” By calling the updated knowledge graph, the LLM can output the latest legal views without retraining. This “knowledge – as – a – service” model greatly enhances the practicality of AI systems.
Finally, the “complementary architecture” of knowledge graphs and LLMs promotes the upgrade of AI from a “tool” to an “intelligent advisor.” The news distinguishes between “intelligent autonomous systems” and “intelligent advisor systems”: the former needs to make independent decisions (such as autonomous driving), while the latter focuses on assisting human judgment (such as legal research and medical diagnosis). In professional fields, the “advisor system” better meets the actual needs—human experts need AI to provide “interpretable suggestions” rather than “substitute decisions.” The combination of the “interpretability” of knowledge graphs and the “natural language interaction” of LLMs exactly meets this requirement: the LLM is responsible for processing natural language queries from users, the knowledge graph provides structured facts and reasoning paths, and the system finally outputs a complete report of “conclusion + basis + related cases.” For example, in medical diagnosis, the system can not only give “recommended medications” but also show “the issuing agency of the medication guide, the latest revision time, and the matching logic with the patient’s medical history,” helping doctors quickly verify the rationality of decisions. This “transparent” auxiliary ability is the key for AI in professional fields to gain trust.
Negative Comments: The Integration of Knowledge Graphs and LLMs Still Faces Multiple Challenges, and Implementation Needs to Cross the “Reality Gap”
Although knowledge graphs provide a “trustworthy foundation” for the professional application of LLMs, their integration is not a “panacea.” From technical implementation to industry adaptation, there are still many real – world challenges. If not handled properly, it may lead to the dilemma of “high investment and poor results” in AI projects.
Firstly, the “construction cost” and “domain barriers” of knowledge graphs may become bottlenecks for implementation. Building a high – quality knowledge graph requires triple investment in “data + experts + technology”: First, it is necessary to integrate multi – source heterogeneous data (such as legal databases, academic papers, and industry reports) and perform pre – processing such as entity extraction and relationship annotation, which places extremely high requirements on data quality and annotation efficiency. Secondly, knowledge in professional fields is highly specialized (such as “hierarchy of precedent validity” and “differences in territorial jurisdiction” in law), and domain experts need to be deeply involved in knowledge modeling. Otherwise, “logical errors” or “missing relationships” are likely to occur. Finally, the maintenance of knowledge graphs requires continuous investment—with the update of domain knowledge (such as the introduction of new regulations), entity relationships need to be dynamically adjusted, which may become a “heavy burden” for small and medium – sized enterprises. For example, a knowledge graph in the legal field may need to integrate tens of thousands of precedents globally, and each new precedent requires manual verification of its association with existing precedents. The complexity of this “knowledge engineering” far exceeds the technical capabilities of ordinary enterprises.
Secondly, there are technical challenges in the “collaborative efficiency” between LLMs and knowledge graphs. The core of a hybrid system is a closed – loop process of “LLM processes natural language → knowledge graph retrieves facts → LLM generates answers,” but this process involves the collaboration of multiple modules, which may lead to response delays or information loss. For example, when a user asks, “In a certain aviation accident, can passengers claim compensation based on the 2019 precedent of the Eleventh Circuit Court?” the LLM needs to accurately extract key entities such as “aviation accident,” “2019,” and “Eleventh Circuit Court.” The knowledge graph needs to quickly retrieve related precedents and verify their validity (whether they have been overturned by subsequent precedents). Finally, the LLM needs to integrate the retrieval results into a natural – language answer. If there is a problem in any link (such as incorrect entity extraction or low graph query efficiency), the system may output incorrect or redundant information. In addition, the “reasoning ability” of knowledge graphs is still limited—although it can handle explicit relationships (such as “Precedent A is overturned by Precedent B”), the reasoning of implicit logic (such as “Whether the core principle of Precedent A applies to a new scenario”) still depends on the “pattern recognition” of the LLM, and the “fuzzy reasoning” of the LLM may introduce uncertainty again.
Thirdly, the positioning of the “intelligent advisor” may deviate from the actual needs. The news emphasizes that professional fields should prioritize the deployment of advisor systems that “assist humans,” but some enterprises may over – emphasize “autonomous decision – making” in pursuit of “technological advancement.” For example, some legal technology companies may promote that their AI can “independently generate legal opinions” instead of “assisting lawyers in verifying cases” to attract customers. This positioning deviation may lead to two risks: One is that the system may cause legal disputes due to over – reliance on the “hallucination” output of the LLM (such as the Schwartz case). The other is that it ignores the “checking role” of human experts, causing users (such as lawyers and doctors) to over – trust AI and weaken their own professional judgment ability. In addition, if the “interaction design” of the advisor system is not user – friendly (such as complex result presentation and unclear verification paths), it may reduce users’ willingness to use it, ultimately resulting in the technology failing to take root.
Advice for Entrepreneurs: From “Technology Stacking” to “Demand – Oriented,” Build a Trustworthy Professional AI System
The discussion about the Schwartz case and knowledge graphs provides key insights for entrepreneurs in the implementation of AI in professional fields: The “trustworthiness” of technology is more important than its “advancement,” and the construction of trustworthiness needs to revolve around the three elements of “demand – architecture – ecosystem.” The following are specific suggestions:
- Clarify the “advisor positioning” and avoid the “substitution illusion”: AI systems in professional fields should focus on “assisting decision – making” rather than “replacing experts.” Entrepreneurs need to clarify the core principle of “human supervision” at the initial stage of product design. For example, in the legal scenario, the cases output by the system should be marked with the “verification status” (verified/unverified), provide links to the original data, and require users (lawyers) to confirm before submission. In the medical scenario, the system should display the “source of the guide” and “evidence level” of the diagnosis basis and prompt doctors to make judgments based on clinical experience. This “shared – responsibility” design can not only reduce legal risks but also enhance users’ trust in the system.
- Prioritize building a “light – weight knowledge graph” and avoid the “big – and – all – encompassing” trap: The construction of knowledge graphs should follow the principle of “Minimum Viable Knowledge.” Entrepreneurs can first focus on vertically segmented fields (such as “precedents for aviation transportation disputes” rather than the entire legal field) and build an initial knowledge graph through a “manual + semi – automated” approach—using LLMs to extract entities and relationships from authoritative databases (such as Westlaw and LexisNexis), and then having domain experts verify key relationships (such as “precedent validity” and “territorial association”). As user needs accumulate, the knowledge coverage can be gradually expanded. This “rapid – iteration” strategy can not only reduce the initial cost but also quickly verify the technical feasibility.
- Optimize the “LLM – KG collaborative process” to improve system efficiency: The performance of a hybrid system depends on the smoothness of the process of “natural language processing – graph query – result generation.” Entrepreneurs can optimize it in the following ways: First, train domain – specific LLMs (such as legal LLMs) to improve the accuracy of entity extraction and intention understanding. Second, perform “hierarchical indexing” on the knowledge graph (such as establishing sub – graphs by “court level” and “case type”) to accelerate query responses. Third, design “dynamic prompt templates” to adjust the generation strategy of the LLM according to the type of user questions (such as “case verification” and “legal analysis”) and avoid redundant information. For example, when a user needs to verify the authenticity of a case, the system should give priority to returning core information such as “existence” and “source database” instead of elaborating on case details.
- Build a “knowledge ecosystem” to reduce maintenance costs: The dynamic update of knowledge graphs requires continuous investment. Entrepreneurs can reduce costs through “user co – creation” or “third – party cooperation.” For example, in the legal field, lawyers can be invited to submit new precedents and mark relationships, and the system can use a reward mechanism (such as points exchange for services) to encourage participation. At the same time, cooperate with authoritative legal databases (such as Pkulaw) to directly access their latest precedent data and reduce duplicate work. In addition, the “automatic extraction” ability of LLMs can be used to regularly scan industry dynamics (such as announcements on court websites), automatically extract new entities, and trigger the manual verification process to achieve “semi – automated” knowledge update.
- Strengthen the “interpretability” design to enhance user trust: Users in professional fields (such as lawyers and doctors) have extremely low tolerance for “black – box decision – making,” and the system needs to provide a clear “reasoning path.” Entrepreneurs can add a “knowledge tracing” function to the product—by clicking on any case in the output results, users can view its associated nodes in the knowledge graph (such as “cited by which precedents” and “whether it has been overturned”), the data source (such as “extracted from Westlaw’s November 2025 update”), and even the key steps of the LLM in processing the problem (such as “recognized the entity ‘Eleventh Circuit Court’ and triggered a search in the precedent database”). This “transparent” design can help users quickly verify the reliability of the system output and thus establish long – term trust.
Conclusion: The lesson of the Schwartz case is not to deny the value of AI in professional fields but to warn that “technology cannot be separated from the knowledge foundation.” For entrepreneurs, the integration of LLMs and knowledge graphs is not an “optional question” but a “must – answer question”—only by building an intelligent advisor system that is “trustworthy, usable, and interpretable” can the professional value of AI be truly unleashed and the mistake of “hallucination – induced misjudgment” be avoided. In the future, the competition of AI in professional fields may shift from a “model parameter competition” to a “knowledge infrastructure competition,” and this is exactly where the opportunities for entrepreneurs lie.
- Startup Commentary”Three post-2005 entrepreneurs are reported to have secured a new financing of 350 million yuan.”
- Startup Commentary”Retired and Reemployed: I Became Everyone’s “Shared Grandma””
- Startup Commentary”YuJian XiaoMian Breaks Issue Price on Listing: Where Lies the Difficulty for Chinese Noodle Restaurants to Break Through in the Market? “
- Startup Commentary”Adjusting Permissions of Doubao Mobile Assistant: AI Phones Are a Flood, but Not a Beast”
- Startup Commentary”Moutai’s Self – rescue and Long – term Concerns”